A suggests that a statistic called the Bayes factor can keep the FDA from approving useless drugs. But, �鶹��ý reviewer F. Perry Wilson, MD, argues that it won't; vigorous defense of the agency's regulatory powers, on the other hand, will.
The long-running cold war between frequentist and Bayesian statisticians got a bit hotter with the publication of this article, appearing in PLOS ONE.

Why are we discussing a somewhat wonky statistical simulation study in a video series meant to discuss breaking medical news stories? Because it bears very much on the developing political situation surrounding the role of the FDA in approving novel drugs.
In his address to a joint session of congress, President Trump said this:
" ... Our slow and burdensome process at the Food and Drug Administration keeps too many advances ... from reaching those in need. If we slash the restraints, not just at the FDA, but across our government, then we will be blessed with far more miracles ... "
What is this "slow and burdensome process"? Well, the FDA is charged with assuring that new drugs are not only safe, but also effective. It's the latter part that I am focusing on today. First, why do we care if a drug is effective, provided it is safe? Won't the free market allow those ineffective drugs to die on the vine? Well, if homeopathy is any example, safe and completely ineffective drugs would be a multi-billion dollar industry.

So let's embrace the idea that the FDA should ensure that drugs, you know, work. How do they do this?
According to their guidance to industry document, they require at least two adequate and well-controlled studies, each convincing on its own:

Two big, expensive clinical trials in other words. The fight over how much "regulation" is going on at the FDA may boil down to a question of how many trials are needed to prove efficacy.
Why two? Why isn't one trial enough? We conventionally define a "positive" study at a P-value of 0.05. A common misconception is that this means that the chance that the drug doesn't work is a mere 5%. Doesn't seem too scary to approve a drug with just a 5% risk that it's actually a dud. But this belief about the p-value is wrong because it doesn't give you any information about the chance of the drug working BEFORE you did the trial. If the intervention was like, rubbing a crystal on your forehead to cure cancer, you wouldn't look at a P-value of 0.05 and say, "huh – I guess I can be 95% certain that crystals on your forehead cure cancer." No, you'd just say, "huh – this is one of the 5% of the times that chance alone will lead to results like this. This study should be repeated."

In fact, if you take a drug you have 10% confidence in and do a single trial that achieves that magic P-value of 0.05, your confidence that the drug actually works should now only be around 68%. Saying that your 68% sure a drug works is probably not good enough for FDA approval. Two studies, though, bumps that post-test probability all the way up to 98%. Now we're talking.
This math comes from Bayes' Theorem, which quantitates the effect of new data on existing probabilities.
The PLOS ONE article suggests that we'll be saved from ineffective drugs getting through the pipeline through the use of something called Bayes factors, which reflect the increase in confidence of efficacy after a trial is conducted, as opposed to the classic P-value.
My position? Both work fine. But here are the arguments they present:
The first issue they bring up is sort of obvious. Assuming you need two positive studies to get your drug approved, why not just do a bunch of studies? It's intuitive that you'll get lucky a couple of times. They quantitate this in the following figure:

In this simulation, the authors imagine 20 trials of a drug which has no biologic effect – crystals on your forehead. Of course, two of those 20 trials might be positive due to chance alone. In those situations, they calculate the Bayes factor, and color it according to how much your confidence should be increased. Black, in this figure, means you should in fact be LESS confident than when you started. See all the black in that figure? That's good because, well, the drug doesn't work.
There's nothing magical to this idea, actually. The Bayes factor is just good at quantitating what your gut is telling you. If only two out of 20 trials of a drug are positive, you shouldn't be that enthusiastic about it. It's a bit of a straw-man argument to imagine that the FDA would look at 20 studies of a drug, only two of which were positive, and go ahead and approve it because two is a magic number. Bayesian or not; that's just not how the FDA works.
But what about the situation where there are only two studies? Two studies, of a totally ineffective drug. Using our P-value threshold, you'd get a lucky break this way one-quarter of one percent of the time. Would the Bayes factor save the FDA from making a grievous error when a pharmaceutical company just gets really lucky?
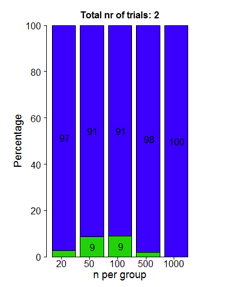
Not really. This figure shows us the Bayes factors that would be associated with those two studies. Blue means you should be very confident that the ineffective drug works. Green means you should be somewhat less confident. Either way, Bayes factors aren't stopping a drug from getting through if Pharma seriously lucks out.
So in the end, this is just a lot of mental gymnastics. If a drug company gets super-lucky, or if you fail to acknowledge 18 negative trials in the face of two positive trials, you're going to approve a bad drug whether you use the P-value or the Bayes factor.
So how do you fix this? Well, you don't rely on statistics entirely. You rely on science. You ensure that you are aware of all the clinical trials involving the drug so you aren't getting presented with the two out of the 20 that worked. This is what mandatory reporting on Clinicaltrials.gov is for, and it is one regulation that is completely vital to ensure drugs actually work. Seriously, we can't roll this one back.
You also look at the pre-trial data. How does the drug work in cells, in animals, in healthy humans, and so on. All should paint a consistent picture, allowing that prior probability of efficacy to be high enough in your mind that the phase III trials can actually be convincing.
This, by the way, is the real job of the FDA. Not to rubber-stamp two positive studies. But to digest the wealth of data and make an informed decision. Is the process onerous? Absolutely. Should it remain so? Without a doubt. Reducing regulations on drug makers will not allow miracle cures to flow like water from the largesse of Big Pharma. The battle to fight is not over which statistical school is more appropriate to interpret your data. The battle we should be fighting is to preserve a scientifically rigorous and independent FDA.
F. Perry Wilson, MD, MSCE, is an assistant professor of medicine at the Yale School of Medicine. He is a �鶹��ý reviewer, and in addition to his video analyses, he authors a blog, The Methods Man. You can follow @methodsmanmd on Twitter.